
Alvo– ensinar aos alunos algoritmos para calcular intervalos de confiança de parâmetros estatísticos.
Durante o processamento de dados estatísticos, a média aritmética calculada, coeficiente de variação, coeficiente de correlação, critérios de diferença e outras estatísticas pontuais devem receber limites de confiança quantitativos, que indicam possíveis flutuações do indicador para cima e para baixo dentro do intervalo de confiança.
Exemplo 3.1
.
A distribuição de cálcio no soro sanguíneo de macacos, conforme previamente estabelecido, é caracterizada pelos seguintes indicadores seletivos: = 11,94 mg%; = 0,127 mg%; n= 100. É necessário determinar o intervalo de confiança para a média geral (  ) com probabilidade de confiança P
= 0,95.
) com probabilidade de confiança P
= 0,95.
A média geral está com certa probabilidade no intervalo:
 , Onde
, Onde 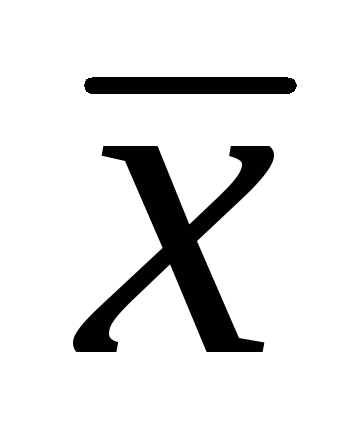 – média aritmética amostral; t- Critério do aluno;
– média aritmética amostral; t- Critério do aluno;  é o erro da média aritmética.
é o erro da média aritmética.
De acordo com a tabela "Valores do critério do aluno" encontramos o valor
 com um nível de confiança de 0,95 e o número de graus de liberdade k\u003d 100-1 \u003d 99. É igual a 1,982. Juntamente com os valores da média aritmética e do erro estatístico, substituímos na fórmula:
com um nível de confiança de 0,95 e o número de graus de liberdade k\u003d 100-1 \u003d 99. É igual a 1,982. Juntamente com os valores da média aritmética e do erro estatístico, substituímos na fórmula:
ou 11.69  12,19
12,19
Assim, com uma probabilidade de 95%, pode-se argumentar que a média geral dessa distribuição normal está entre 11,69 e 12,19 mg%.
Exemplo 3.2
. Determine os limites do intervalo de confiança de 95% para a variância geral (  ) distribuição de cálcio no sangue de macacos, se for sabido que
) distribuição de cálcio no sangue de macacos, se for sabido que  = 1,60, com n
= 100.
= 1,60, com n
= 100.
Para resolver o problema, você pode usar a seguinte fórmula:
Onde  é o erro estatístico da variância.
é o erro estatístico da variância.
Encontre o erro de variação da amostra usando a fórmula:  . É igual a 0,11. Significado t- critério com uma probabilidade de confiança de 0,95 e o número de graus de liberdade k= 100–1 = 99 é conhecido do exemplo anterior.
. É igual a 0,11. Significado t- critério com uma probabilidade de confiança de 0,95 e o número de graus de liberdade k= 100–1 = 99 é conhecido do exemplo anterior.
Vamos usar a fórmula e obter:
ou 1,38  1,82
1,82
Mais precisamente intervalo de confiança variância geral pode ser construída usando  (qui-quadrado) - Teste de Pearson. Os pontos críticos para este critério são dados em uma tabela especial. Ao usar o critério
(qui-quadrado) - Teste de Pearson. Os pontos críticos para este critério são dados em uma tabela especial. Ao usar o critério  um nível de significância bilateral é usado para construir um intervalo de confiança. Para o limite inferior, o nível de significância é calculado pela fórmula
um nível de significância bilateral é usado para construir um intervalo de confiança. Para o limite inferior, o nível de significância é calculado pela fórmula  , para a parte superior
, para a parte superior  . Por exemplo, para um nível de confiança
. Por exemplo, para um nível de confiança  =
0,99
=
0,99 = 0,010,
= 0,010, = 0,990. Assim, de acordo com a tabela de distribuição de valores críticos
= 0,990. Assim, de acordo com a tabela de distribuição de valores críticos  , com os níveis de confiança calculados e o número de graus de liberdade k= 100 – 1= 99, encontre os valores
, com os níveis de confiança calculados e o número de graus de liberdade k= 100 – 1= 99, encontre os valores  e
e  . Nós temos
. Nós temos  é igual a 135,80, e
é igual a 135,80, e  é igual a 70,06.
é igual a 70,06.
Para encontrar os limites de confiança da variância geral usando  usamos as fórmulas: para o limite inferior
usamos as fórmulas: para o limite inferior 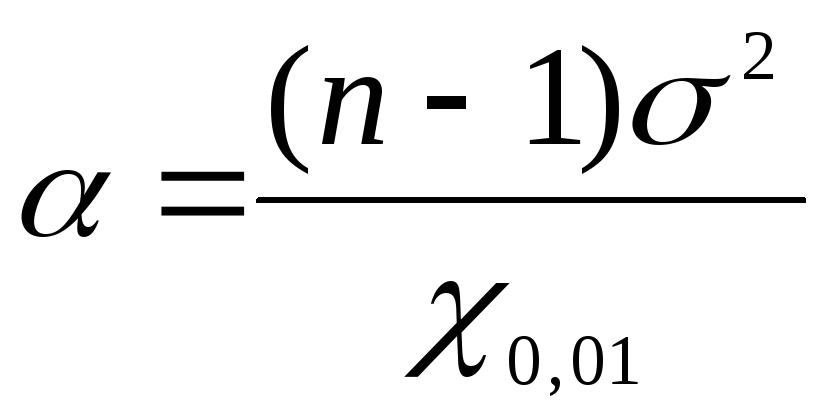 , para o limite superior
, para o limite superior  . Substitua os dados da tarefa pelos valores encontrados
. Substitua os dados da tarefa pelos valores encontrados  em fórmulas:
em fórmulas:  =
1,17;
=
1,17; = 2,26. Assim, com um nível de confiança P= 0,99 ou 99%, a variância geral situar-se-á no intervalo de 1,17 a 2,26 mg% inclusive.
= 2,26. Assim, com um nível de confiança P= 0,99 ou 99%, a variância geral situar-se-á no intervalo de 1,17 a 2,26 mg% inclusive.
Exemplo 3.3 . Entre as 1.000 sementes de trigo do lote que chegaram ao elevador, foram encontradas 120 sementes infectadas com ergot. É necessário determinar os limites prováveis da proporção total de sementes infectadas em um determinado lote de trigo.
Os limites de confiança para a ação geral para todos os seus valores possíveis devem ser determinados pela fórmula:
 ,
,
Onde n é o número de observações; mé o número absoluto de um dos grupos; té o desvio normalizado.
A fração amostral de sementes infectadas é igual a  ou 12%. Com um nível de confiança R= 95% de desvio normalizado ( t-Critério do aluno para k
=
ou 12%. Com um nível de confiança R= 95% de desvio normalizado ( t-Critério do aluno para k
=
 )t
= 1,960.
)t
= 1,960.
Substituímos os dados disponíveis na fórmula:
Assim, os limites do intervalo de confiança são  = 0,122–0,041 = 0,081 ou 8,1%;
= 0,122–0,041 = 0,081 ou 8,1%;  = 0,122 + 0,041 = 0,163, ou 16,3%.
= 0,122 + 0,041 = 0,163, ou 16,3%.
Assim, com um nível de confiança de 95%, pode-se afirmar que a proporção total de sementes infectadas está entre 8,1 e 16,3%.
Exemplo 3.4 . O coeficiente de variação, que caracteriza a variação de cálcio (mg%) no soro sanguíneo de macacos, foi igual a 10,6%. Tamanho da amostra n= 100. É necessário determinar os limites do intervalo de confiança de 95% para o parâmetro geral cv.
Limites de confiança para o coeficiente geral de variação cv são determinadas pelas seguintes fórmulas:
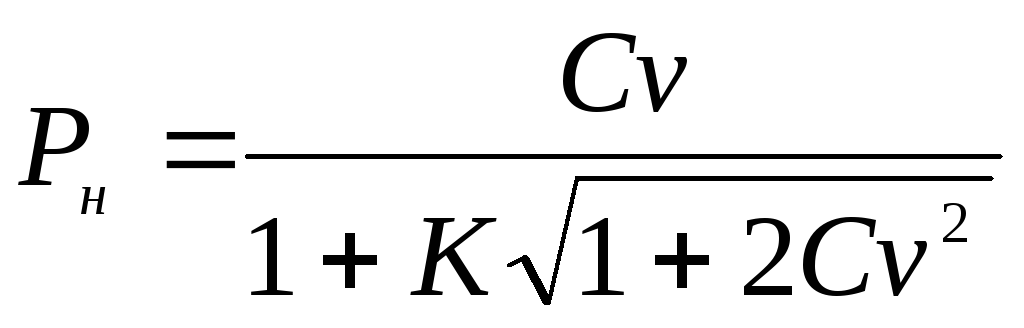 e
e  , Onde k
valor intermediário calculado pela fórmula
, Onde k
valor intermediário calculado pela fórmula  .
.
Sabendo que com um nível de confiança R= 95% de desvio normalizado (teste t de Student para k
=
 )t
= 1,960, pré-calcule o valor PARA:
)t
= 1,960, pré-calcule o valor PARA:
 .
.
 ou 9,3%
ou 9,3%
 ou 12,3%
ou 12,3%
Assim, o coeficiente geral de variação com probabilidade de confiança de 95% situa-se na faixa de 9,3 a 12,3%. Com amostras repetidas, o coeficiente de variação não excederá 12,3% e não cairá abaixo de 9,3% em 95 casos em 100.
Perguntas para o autocontrole:

Tarefas para solução independente.
1. O percentual médio de gordura no leite para lactação de vacas mestiças de Kholmogory foi o seguinte: 3,4; 3.6; 3.2; 3.1; 2.9; 3.7; 3.2; 3.6; 4,0; 3.4; 4.1; 3,8; 3.4; 4,0; 3.3; 3.7; 3,5; 3.6; 3.4; 3.8. Defina intervalos de confiança para a média geral em um nível de confiança de 95% (20 pontos).
2. Em 400 plantas de centeio híbrido, as primeiras flores apareceram em média 70,5 dias após a semeadura. O desvio padrão foi de 6,9 dias. Determine o erro da média e os intervalos de confiança para a média e variância da população em um nível de significância C= 0,05 e C= 0,01 (25 pontos).
3. Ao estudar o comprimento das folhas de 502 espécimes de morangos de jardim, foram obtidos os seguintes dados:
 = 7,86 cm; σ = 1,32 cm,
= 7,86 cm; σ = 1,32 cm,  \u003d ± 0,06 cm Determine os intervalos de confiança para a média aritmética da população com níveis de significância de 0,01; 0,02; 0,05. (25 pontos).
\u003d ± 0,06 cm Determine os intervalos de confiança para a média aritmética da população com níveis de significância de 0,01; 0,02; 0,05. (25 pontos).
4. Ao examinar 150 homens adultos, a altura média foi de 167 cm e σ \u003d 6 cm Quais são os limites da média geral e da variância geral com uma probabilidade de confiança de 0,99 e 0,95? (25 pontos).
5. A distribuição de cálcio no soro sanguíneo de macacos é caracterizada pelos seguintes indicadores seletivos:
 = 11,94 mg%, σ
= 1,27, n
= 100. Trace um intervalo de confiança de 95% para a média populacional dessa distribuição. Calcule o coeficiente de variação (25 pontos).
= 11,94 mg%, σ
= 1,27, n
= 100. Trace um intervalo de confiança de 95% para a média populacional dessa distribuição. Calcule o coeficiente de variação (25 pontos).
6. Foi estudado o conteúdo de nitrogênio total no plasma sanguíneo de ratos albinos com 37 e 180 dias de idade. Os resultados são expressos em gramas por 100 cm 3 de plasma. Aos 37 dias de idade, 9 ratos apresentaram: 0,98; 0,83; 0,99; 0,86; 0,90; 0,81; 0,94; 0,92; 0,87. Aos 180 dias de idade, 8 ratas apresentaram: 1,20; 1.18; 1,33; 1.21; 1,20; 1.07; 1.13; 1.12. Defina intervalos de confiança para a diferença com um nível de confiança de 0,95 (50 pontos).
7. Determine os limites do intervalo de confiança de 95% para a variância geral da distribuição de cálcio (mg%) no soro sanguíneo de macacos, se para esta distribuição o tamanho da amostra n = 100, o erro estatístico da variância da amostra s σ 2 = 1,60 (40 pontos).
8. Determine os limites do intervalo de confiança de 95% para a variância geral da distribuição de 40 espiguetas de trigo ao longo do comprimento (σ 2 = 40,87 mm 2). (25 pontos).
9. O tabagismo é considerado o principal fator predisponente à doença pulmonar obstrutiva. O tabagismo passivo não é considerado tal fator. Os cientistas questionaram a segurança do tabagismo passivo e examinaram as vias aéreas em não fumantes, fumantes passivos e ativos. Para caracterizar o estado do trato respiratório, tomamos um dos indicadores da função da respiração externa - a velocidade volumétrica máxima do meio da expiração. Uma diminuição neste indicador é um sinal de desobstrução das vias aéreas. Os dados da pesquisa são mostrados na tabela.
|
Número de examinados |
Taxa de fluxo expiratório médio máximo, l/s |
||
|
Desvio padrão |
|||
|
não fumantes |
|||
|
trabalhar em uma área não fumante | |||
|
trabalhar em uma sala cheia de fumaça | |||
|
fumantes |
|||
|
fumar um pequeno número de cigarros | |||
|
número médio de fumantes de cigarro | |||
|
fumar um grande número de cigarros | |||
Na tabela, encontre os intervalos de confiança de 95% para a média geral e a variância geral para cada um dos grupos. Quais são as diferenças entre os grupos? Apresentar os resultados graficamente (25 pontos).
10. Determine os limites dos intervalos de confiança de 95% e 99% para a variância geral do número de leitões em 64 partos, se o erro estatístico da variância da amostra s σ 2 = 8,25 (30 pontos).
11. Sabe-se que o peso médio dos coelhos é de 2,1 kg. Determine os limites dos intervalos de confiança de 95% e 99% para a média geral e variância quando n= 30, σ = 0,56 kg (25 pontos).
12. Em 100 espigas, o teor de grãos da espiga foi medido ( x), comprimento do espigão ( Y) e a massa de grãos na espiga ( Z). Encontre intervalos de confiança para a média geral e variância para P 1
= 0,95, P 2
= 0,99, P 3
= 0,999 se
 = 19, = 6,766 cm, = 0,554 g; σ x 2 = 29,153, σ y 2 = 2,111, σ z 2 = 0,064 (25 pontos).
= 19, = 6,766 cm, = 0,554 g; σ x 2 = 29,153, σ y 2 = 2,111, σ z 2 = 0,064 (25 pontos).
13. Em 100 espigas de trigo de inverno selecionadas aleatoriamente, o número de espiguetas foi contado. O conjunto amostral foi caracterizado pelos seguintes indicadores:
 = 15 espiguetas e σ = 2,28 unid. Determine a precisão com que o resultado médio é obtido (
= 15 espiguetas e σ = 2,28 unid. Determine a precisão com que o resultado médio é obtido (  ) e trace o intervalo de confiança para a média geral e variância em níveis de significância de 95% e 99% (30 pontos).
) e trace o intervalo de confiança para a média geral e variância em níveis de significância de 95% e 99% (30 pontos).
14. O número de costelas nas conchas de um molusco fóssil ortambonitas caligrama:
Sabe-se que n = 19, σ = 4,25. Determine os limites do intervalo de confiança para a média geral e a variância geral em um nível de significância C = 0,01 (25 pontos).
15. Para determinar a produção de leite em uma fazenda leiteira comercial, a produtividade de 15 vacas foi determinada diariamente. De acordo com os dados do ano, cada vaca deu em média a seguinte quantidade de leite por dia (l): 22; 19; 25; vinte; 27; 17; trinta; 21; dezoito; 24; 26; 23; 25; vinte; 24. Trace os intervalos de confiança para a variância geral e a média aritmética. Podemos esperar que a produção média anual de leite por vaca seja de 10.000 litros? (50 pontos).
16. A fim de determinar a produtividade média de trigo da fazenda, foram realizadas roçadas em parcelas amostrais de 1, 3, 2, 5, 2, 6, 1, 3, 2, 11 e 2 ha. A produtividade (c/ha) das parcelas foi de 39,4; 38; 35,8; 40; 35; 42,7; 39,3; 41,6; 33; 42; 29 respectivamente. Traçar intervalos de confiança para a variância geral e a média aritmética. É possível esperar que o rendimento médio da empresa agrícola seja de 42 c/ha? (50 pontos).
Vamos construir um intervalo de confiança no MS EXCEL para estimar o valor médio da distribuição no caso de um valor conhecido da variância.
Claro que a escolha nível de confiança depende completamente da tarefa em questão. Assim, o grau de confiança do passageiro aéreo na confiabilidade da aeronave, é claro, deve ser maior do que o grau de confiança do comprador na confiabilidade da lâmpada.
Vamos supor que de população tendo tomado amostra tamanho n. É assumido que desvio padrão esta distribuição é conhecida. Necessário com base nisso amostras avaliar o desconhecido média de distribuição(μ, ) e construa o correspondente bilateral intervalo de confiança.
Como é conhecido de Estatisticas(vamos chamá-lo X cf) é estimativa imparcial da média isto população e tem a distribuição N(μ;σ 2 /n).
Observação: E se você precisar construir intervalo de confiança no caso da distribuição, que não é normal? Nesse caso, vem em socorro, que diz que com bastante tamanho grande amostras n da distribuição não- normal, distribuição amostral de estatísticas Х av vai ser aproximadamente corresponder distribuição normal com parâmetros N(μ;σ 2 /n).
Então, ponto estimado meio valores de distribuição nós temos é média da amostra, ou seja X cf. Agora vamos nos ocupar intervalo de confiança.
Normalmente, conhecendo a distribuição e seus parâmetros, podemos calcular a probabilidade de uma variável aleatória assumir um valor em um determinado intervalo. Agora vamos fazer o oposto: encontre o intervalo no qual a variável aleatória cai com uma dada probabilidade. Por exemplo, de propriedades distribuição normal sabe-se que com uma probabilidade de 95%, uma variável aleatória distribuída lei normal, cairá dentro do intervalo de aproximadamente +/- 2 de valor médio(ver artigo sobre). Este intervalo servirá como nosso protótipo para intervalo de confiança.
Agora vamos ver se conhecemos a distribuição , calcular esse intervalo? Para responder à pergunta, devemos especificar a forma de distribuição e seus parâmetros.
Sabemos que a forma de distribuição é distribuição normal(lembre-se disso nós estamos falando cerca de distribuição de amostras Estatisticas X cf).
O parâmetro μ é desconhecido para nós (só precisa ser estimado usando intervalo de confiança), mas temos sua estimativa X cf, calculado com base em amostra, que pode ser usado.
O segundo parâmetro é amostra média desvio padrão será conhecido, é igual a σ/√n.
Porque não sabemos μ, então vamos construir o intervalo +/- 2 desvio padrão Não de valor médio, mas de sua estimativa conhecida X cf. Aqueles. ao calcular intervalo de confiança NÃO vamos supor que X cf cairá dentro do intervalo +/- 2 desvio padrão de μ com uma probabilidade de 95%, e assumiremos que o intervalo é +/- 2 desvio padrão a partir de X cf com uma probabilidade de 95% cobrirá μ - a média da população em geral, do qual amostra. Essas duas declarações são equivalentes, mas a segunda declaração nos permite construir intervalo de confiança.
Além disso, refinamos o intervalo: uma variável aleatória distribuída sobre lei normal, com uma probabilidade de 95% cai dentro do intervalo +/- 1,960 desvio padrão, não +/- 2 desvio padrão. Isso pode ser calculado usando a fórmula \u003d NORM.ST.OBR ((1 + 0,95) / 2), cm. arquivo de amostra Espaçamento entre folhas.

Agora podemos formular uma declaração probabilística que nos servirá para formar intervalo de confiança:
"A probabilidade de população média localizado a partir de amostra média dentro de 1.960" desvios padrão da média amostral", é igual a 95%.
O valor de probabilidade mencionado na declaração tem um nome especial , que está associado a nível de significância α (alfa) por uma expressão simples nível de confiança =1 -α . No nosso caso nível de significância α =1-0,95=0,05 .
Agora, com base nessa declaração probabilística, escrevemos uma expressão para calcular intervalo de confiança:

onde Zα/2 – padrão distribuição normal(tal valor de uma variável aleatória z, o que P(z>=Zα/2 )=α/2).
Observação: α/2-quantil superior define a largura intervalo de confiança dentro desvio padrão média da amostra. α/2-quantil superior padrão distribuição normalé sempre maior que 0, o que é muito conveniente.
No nosso caso, em α=0,05, α/2-quantil superior é igual a 1,960. Para outros níveis de significância α (10%; 1%) α/2-quantil superior Zα/2 pode ser calculado usando a fórmula \u003d NORM.ST.OBR (1-α / 2) ou, se conhecido nível de confiança, =NORM.ST.OBR((1+nível de confiança)/2).
Normalmente ao construir intervalos de confiança para estimar a média usarem apenas α superior/2-quantil e não use menor α/2-quantil. Isso é possível porque padrão distribuição normal simétrica em relação ao eixo x ( densidade de sua distribuição simétrico sobre média, ou seja 0). Portanto, não há necessidade de calcular α/2-quantil inferior(é chamado simplesmente de α /2-quantil), Porque é igual α superior/2-quantil com um sinal de menos.
Lembre-se de que, independentemente da forma da distribuição de x, a variável aleatória correspondente X cf distribuído aproximadamente multar N(μ;σ 2 /n) (ver artigo sobre). Portanto, em caso Geral, a expressão acima para intervalo de confiançaé apenas aproximado. Se x é distribuído por lei normal N(μ;σ 2 /n), então a expressão para intervalo de confiançaé preciso.
Vamos resolver o problema.
Tempo de resposta componente eletronico no sinal de entrada é uma característica importante do dispositivo. Um engenheiro deseja traçar um intervalo de confiança para o tempo médio de resposta com um nível de confiança de 95%. Por experiência anterior, o engenheiro sabe que o desvio padrão do tempo de resposta é de 8 ms. Sabe-se que o engenheiro fez 25 medições para estimar o tempo de resposta, o valor médio foi de 78 ms.
Solução: Engenheiro quer saber o tempo de resposta aparelho eletrônico, mas ele entende que o tempo de resposta não é fixo, mas uma variável aleatória que tem sua própria distribuição. Portanto, o melhor que ele pode esperar é determinar os parâmetros e a forma dessa distribuição.
Infelizmente, pela condição do problema, não sabemos a forma de distribuição do tempo de resposta (não precisa ser normal). , esta distribuição também é desconhecida. Só ele é conhecido desvio padrãoσ=8. Portanto, embora não possamos calcular as probabilidades e construir intervalo de confiança.
No entanto, embora não conheçamos a distribuição Tempo resposta separada, sabemos que de acordo com CPT, distribuição de amostras tempo médio de respostaé aproximadamente normal(vamos assumir que as condições CPT são executados, porque o tamanho amostras grande o suficiente (n = 25)) .
Além disso, média esta distribuição é igual a valor médio distribuições de resposta unitária, ou seja, μ. MAS desvio padrão desta distribuição (σ/√n) pode ser calculada usando a fórmula =8/ROOT(25) .
Sabe-se também que o engenheiro recebeu ponto estimado parâmetro μ igual a 78 ms (X cf). Portanto, agora podemos calcular as probabilidades, porque conhecemos a forma de distribuição ( normal) e seus parâmetros (Х ср e σ/√n).
Engenheiro quer saber valor esperadoμ da distribuição do tempo de resposta. Como dito acima, este μ é igual a expectativa da distribuição amostral do tempo médio de resposta. Se usarmos distribuição normal N(X cf; σ/√n), então o μ desejado estará na faixa +/-2*σ/√n com uma probabilidade de aproximadamente 95%.
Nível de significânciaé igual a 1-0,95=0,05.
Finalmente, encontre a borda esquerda e direita intervalo de confiança.
Borda esquerda: \u003d 78-NORM.ST.INR (1-0,05 / 2) * 8 / ROOT (25) =
74,864
Borda direita: \u003d 78 + NORM. ST. OBR (1-0,05 / 2) * 8 / ROOT (25) \u003d 81.136
Borda esquerda: =NORM.INV(0,05/2, 78, 8/SQRT(25))
Borda direita: =NORM.INV(1-0,05/2, 78, 8/SQRT(25))
Responda: intervalo de confiança no nível de confiança de 95% e σ=8msegé igual a 78+/-3.136ms
NO arquivo de exemplo na folha Sigma conhecido criou um formulário para cálculo e construção bilateral intervalo de confiança para arbitrário amostras com um dado σ e nível de significância.

Se os valores amostras estão no intervalo B20:B79
, uma nível de significância igual a 0,05; então fórmula do MS EXCEL:
=MÉDIA(B20:B79)-CONFIANÇA(0,05,σ, CONTAGEM(B20:B79))
retornará a borda esquerda intervalo de confiança.
O mesmo limite pode ser calculado usando a fórmula:
=MÉDIA(B20:B79)-NORM.ST.INV(1-0,05/2)*σ/SQRT(CONTAGEM(B20:B79))
Observação: A função CONFIDENCE.NORM() apareceu no MS EXCEL 2010. Mais primeiras versões O MS EXCEL usou a função TRUST().
E outros. Todos eles são estimativas de suas contrapartes teóricas, que poderiam ser obtidas se não houvesse uma amostra, mas população. Mas, infelizmente, a população em geral é muito cara e muitas vezes indisponível.
Qualquer estimativa de amostra tem alguma dispersão, porque é uma variável aleatória dependendo dos valores em uma determinada amostra. Portanto, para inferências estatísticas mais confiáveis, deve-se conhecer não apenas a estimativa pontual, mas também o intervalo, que com alta probabilidade γ (gama) cobre o indicador estimado θ (teta).
Formalmente, esses são dois desses valores (estatísticas) T1(X) e T2(X), o que T1< T 2 , para o qual em um determinado nível de probabilidade γ condição é satisfeita:
Em suma, é provável γ ou mais o valor verdadeiro está entre os pontos T1(X) e T2(X), que são chamados de limites inferior e superior intervalo de confiança.
Uma das condições para a construção de intervalos de confiança é a sua estreiteza máxima, ou seja, deve ser o mais curto possível. O desejo é bastante natural, porque. o pesquisador tenta localizar com mais precisão a descoberta do parâmetro desejado.
Segue-se que o intervalo de confiança deve cobrir as probabilidades máximas da distribuição. e a partitura em si esteja no centro.
![]()
Ou seja, a probabilidade de desvio (do verdadeiro indicador da estimativa) para cima é igual à probabilidade de desvio para baixo. Também deve ser observado que, para distribuições assimétricas, o intervalo à direita não é igual ao intervalo à esquerda.
A figura acima mostra claramente que quanto maior o nível de confiança, maior o intervalo - uma relação direta.
Esta foi uma pequena introdução à teoria da estimativa de intervalo de parâmetros desconhecidos. Vamos prosseguir para encontrar os limites de confiança para expectativa matemática.
Se os dados originais forem distribuídos por , a média será um valor normal. Isso decorre da regra de que uma combinação linear de valores normais também possui uma distribuição normal. Portanto, para calcular as probabilidades, poderíamos usar o aparato matemático da lei da distribuição normal.
No entanto, isso exigirá o conhecimento de dois parâmetros - o valor esperado e a variância, que geralmente não são conhecidos. Você pode, é claro, usar estimativas em vez de parâmetros (média aritmética e ), mas a distribuição da média não será totalmente normal, será ligeiramente achatada. O cidadão irlandês William Gosset notou habilmente esse fato quando publicou sua descoberta na edição de março de 1908 da Biometrica. Para fins de sigilo, Gosset assinou com Student. É assim que a distribuição t de Student apareceu.
No entanto, a distribuição normal de dados, usada por K. Gauss na análise de erros em observações astronômicas, é extremamente rara na vida terrestre e é bastante difícil estabelecê-la (são necessárias cerca de 2 mil observações para alta precisão). Portanto, é melhor abandonar a suposição de normalidade e usar métodos que não dependam da distribuição dos dados originais.
Surge a pergunta: qual é a distribuição da média aritmética se for calculada a partir dos dados de uma distribuição desconhecida? A resposta é dada pelo conhecido na teoria da probabilidade Teorema do limite central(CPT). Em matemática, existem várias versões dela (as formulações foram refinadas ao longo dos anos), mas todas elas, grosso modo, se resumem à afirmação de que a soma um grande número independente variáveis aleatórias obedece à lei da distribuição normal.
Ao calcular a média aritmética, a soma das variáveis aleatórias é usada. A partir disso, verifica-se que a média aritmética tem uma distribuição normal, na qual o valor esperado é o valor esperado dos dados iniciais e a variância é .
Pessoas pequenas sabemos provar a CLT, mas vamos verificar isso com o auxílio de um experimento realizado no Excel. Vamos simular uma amostra de 50 variáveis aleatórias uniformemente distribuídas (usando funções do Excel ALEATÓRIO ENTRE). Em seguida, faremos 1.000 dessas amostras e calcularemos a média aritmética para cada uma. Vejamos sua distribuição.

Pode-se observar que a distribuição da média está próxima da lei normal. Se o volume de amostras e seu número forem ainda maiores, a semelhança será ainda melhor.
Agora que vimos por nós mesmos a validade do CLT, podemos, usando , calcular os intervalos de confiança para a média aritmética, que cobrem a verdadeira média ou expectativa matemática com uma dada probabilidade.
Para estabelecer os limites superior e inferior, é necessário conhecer os parâmetros da distribuição normal. Como regra, eles não são, portanto, as estimativas são usadas: média aritmética e variância amostral. Novamente, este método fornece uma boa aproximação apenas para grandes amostras. Quando as amostras são pequenas, geralmente é recomendável usar a distribuição de Student. Não acredite! A distribuição de Student para a média ocorre apenas quando os dados originais têm distribuição normal, ou seja, quase nunca. Portanto, é melhor definir imediatamente a barra mínima para a quantidade de dados necessários e usar métodos assintoticamente corretos. Dizem que 30 observações são suficientes. Tome 50 - você não pode errar.
![]()
T 1.2 são os limites inferior e superior do intervalo de confiança
- média aritmética amostral
s0– desvio padrão da amostra (imparcial)
n - tamanho da amostra
γ – nível de confiança (geralmente igual a 0,9, 0,95 ou 0,99)
c γ = Φ -1 ((1+γ)/2)é o recíproco da função de distribuição normal padrão. Em termos simples, este é o número de erros padrão da média aritmética para o limite inferior ou superior (as três probabilidades indicadas correspondem aos valores de 1,64, 1,96 e 2,58).
A essência da fórmula é que a média aritmética é tomada e, em seguida, uma certa quantia é separada dela ( com γ) erros padrão ( s 0 /√n). Tudo é conhecido, pegue e conte.
Antes do uso em massa de PCs, para obter os valores da função de distribuição normal e sua inversa, eles usavam . Eles ainda são usados, mas é mais eficiente recorrer a fórmulas prontas do Excel. Todos os elementos da fórmula acima ( , e ) podem ser facilmente calculados no Excel. Mas também existe uma fórmula pronta para calcular o intervalo de confiança - NORMA DE CONFIANÇA. Sua sintaxe é a seguinte.
NORMA DE CONFIANÇA(alfa, standard_dev, tamanho)
alfa– nível de significância ou nível de confiança, que na notação acima é igual a 1-γ, ou seja, a probabilidade de que a matemáticaa expectativa estará fora do intervalo de confiança. Com um nível de confiança de 0,95, alfa é 0,05 e assim por diante.
standard_offé o desvio padrão dos dados de amostra. Você não precisa calcular o erro padrão, o Excel irá dividir pela raiz de n.
o tamanho– tamanho da amostra (n).
O resultado da função CONFIDENCE.NORM é o segundo termo da fórmula para calcular o intervalo de confiança, ou seja, meio intervalo. Consequentemente, os pontos inferior e superior são a média ± o valor obtido.
Assim, é possível construir um algoritmo universal para cálculo de intervalos de confiança para a média aritmética, que independe da distribuição dos dados iniciais. O preço da universalidade é sua natureza assintótica, ou seja, a necessidade de usar amostras relativamente grandes. No entanto, no século tecnologias modernas coletar a quantidade certa de dados geralmente não é difícil.
(módulo 111)
Um dos principais problemas resolvidos em estatística é. Em poucas palavras, sua essência é essa. É feita uma suposição, por exemplo, de que a expectativa da população em geral é igual a algum valor. Em seguida, é construída a distribuição das médias amostrais, que podem ser observadas com uma dada expectativa. A seguir, veremos onde está localizada a média real nessa distribuição condicional. Se ultrapassar os limites permitidos, então o aparecimento de tal média é muito improvável, e com uma única repetição do experimento é quase impossível, o que contradiz a hipótese apresentada, que é rejeitada com sucesso. Se a média não ultrapassar o nível crítico, a hipótese não é rejeitada (mas também não é provada!).
Assim, com a ajuda dos intervalos de confiança, no nosso caso da expectativa, você também pode testar algumas hipóteses. É muito fácil de fazer. Suponha que a média aritmética para alguma amostra seja 100. A hipótese está sendo testada de que a expectativa é, digamos, 90. Ou seja, se colocarmos a questão primitivamente, soa assim: pode ser que, com o valor verdadeiro do média igual a 90, a média observada foi 100?
Para responder a esta pergunta, informações adicionais sobre a média desvio padrão e tamanho da amostra. Digamos que o desvio padrão seja 30 e o número de observações seja 64 (para extrair facilmente a raiz). Então o erro padrão da média é 30/8 ou 3,75. Para calcular o intervalo de confiança de 95%, será necessário diferir para ambos os lados da média em dois erros padrão(mais precisamente, por 1,96). O intervalo de confiança será de aproximadamente 100 ± 7,5, ou de 92,5 a 107,5.
O raciocínio adicional é o seguinte. Se o valor testado estiver dentro do intervalo de confiança, ele não contradiz a hipótese, pois enquadra-se nos limites das flutuações aleatórias (com uma probabilidade de 95%). Se o ponto testado estiver fora do intervalo de confiança, então a probabilidade de tal evento é muito pequena, em qualquer caso abaixo do nível aceitável. Portanto, a hipótese é rejeitada por contradizer os dados observados. No nosso caso, a hipótese de expectativa está fora do intervalo de confiança (o valor testado de 90 não está incluído no intervalo de 100±7,5), pelo que deve ser rejeitada. Respondendo à pergunta primitiva acima, deve-se dizer: não, não pode, em qualquer caso, isso acontece muito raramente. Freqüentemente, isso indica uma probabilidade específica de rejeição errônea da hipótese (nível p), e não um determinado nível, segundo o qual o intervalo de confiança foi construído, mas mais sobre isso em outra ocasião.
Como você pode ver, não é difícil construir um intervalo de confiança para a média (ou expectativa matemática). O principal é pegar a essência, e aí as coisas vão. Na prática, a maioria usa o intervalo de confiança de 95%, que tem cerca de dois erros padrão de largura em cada lado da média.
É tudo por agora. Tudo de bom!
Intervalo de confiança(IC; em inglês, intervalo de confiança - CI) obtido no estudo na amostra dá uma medida da precisão (ou incerteza) dos resultados do estudo, a fim de tirar conclusões sobre a população de todos esses pacientes (população geral ). A definição correta de IC 95% pode ser formulada da seguinte forma: 95% desses intervalos conterão o valor verdadeiro na população. Essa interpretação é um pouco menos precisa: CI é a faixa de valores dentro da qual você pode ter 95% de certeza de que contém o valor verdadeiro. Ao usar o IC, a ênfase está na determinação do efeito quantitativo, em oposição ao valor P, que é obtido como resultado do teste de significância estatística. O valor P não avalia qualquer quantidade, mas serve como uma medida da força da evidência contra a hipótese nula de "nenhum efeito". O valor de P por si só não nos diz nada sobre a magnitude da diferença, ou mesmo sobre sua direção. Portanto, valores independentes de P são absolutamente não informativos em artigos ou resumos. Em contraste, o IC indica tanto a quantidade de efeito de interesse imediato, como a utilidade de um tratamento, quanto a força da evidência. Portanto, o DI está diretamente relacionado à prática do DM.
Abordagem de avaliação para análise estatística, ilustrado pelo IC, visa medir a quantidade do efeito de interesse (sensibilidade do teste diagnóstico, incidência prevista, redução do risco relativo com o tratamento, etc.), bem como medir a incerteza desse efeito. Na maioria das vezes, o IC é a faixa de valores em ambos os lados da estimativa em que o valor verdadeiro provavelmente está, e você pode ter 95% de certeza disso. A convenção para usar a probabilidade de 95% é arbitrária, assim como o valor de P<0,05 для оценки статистической значимости, и авторы иногда используют 90% или 99% ДИ. Заметим, что слово «интервал» означает диапазон величин и поэтому стоит в единственном числе. Две величины, которые ограничивают интервал, называются «доверительными пределами».
O IC baseia-se na ideia de que o mesmo estudo realizado em diferentes conjuntos de pacientes não produziria resultados idênticos, mas que seus resultados seriam distribuídos em torno do valor verdadeiro, mas desconhecido. Em outras palavras, o IC descreve isso como "variabilidade dependente da amostra". O IC não reflete incerteza adicional devido a outras causas; em particular, não inclui o impacto da perda seletiva de pacientes no rastreamento, adesão insatisfatória ou medição de resultados imprecisa, falta de cegamento, etc. A IC, portanto, sempre subestima a quantidade total de incerteza.
Tabela A1.1. Erros padrão e intervalos de confiança para algumas medidas clínicas
Normalmente, o IC é calculado a partir de uma estimativa observada de uma medida quantitativa, como a diferença (d) entre duas proporções e o erro padrão (SE) na estimativa dessa diferença. O IC aproximado de 95% assim obtido é d ± 1,96 SE. A fórmula muda de acordo com a natureza da medida de resultado e a cobertura do IC. Por exemplo, em um estudo randomizado controlado por placebo de vacina acelular contra coqueluche, a tosse convulsa se desenvolveu em 72 de 1.670 (4,3%) lactentes que receberam a vacina e 240 de 1.665 (14,4%) no grupo de controle. A diferença percentual, conhecida como redução absoluta do risco, é de 10,1%. O SE dessa diferença é de 0,99%. Consequentemente, o IC de 95% é 10,1% + 1,96 x 0,99%, ou seja, de 8,2 a 12,0.
Apesar das diferentes abordagens filosóficas, ICs e testes de significância estatística estão intimamente relacionados matematicamente.
Assim, o valor de P é “significativo”, ou seja, R<0,05 соответствует 95% ДИ, который исключает величину эффекта, указывающую на отсутствие различия. Например, для различия между двумя средними пропорциями это ноль, а для относительного риска или отношения шансов - единица. При некоторых обстоятельствах эти два подхода могут быть не совсем эквивалентны. Преобладающая точка зрения: оценка с помощью ДИ - предпочтительный подход к суммированию результатов исследования, но ДИ и величина Р взаимодополняющи, и во многих статьях используются оба способа представления результатов.
A incerteza (inexatidão) da estimativa, expressa em CI, está amplamente relacionada à raiz quadrada do tamanho da amostra. Amostras pequenas fornecem menos informações do que amostras grandes, e os ICs são correspondentemente mais amplos em amostras menores. Por exemplo, um artigo comparando o desempenho de três testes usados para diagnosticar a infecção por Helicobacter pylori relatou uma sensibilidade do teste respiratório da ureia de 95,8% (95% CI 75-100). Embora o número de 95,8% pareça impressionante, o pequeno tamanho da amostra de 24 pacientes adultos com H. pylori significa que há uma incerteza significativa nessa estimativa, conforme demonstrado pelo IC amplo. De fato, o limite inferior de 75% é muito inferior à estimativa de 95,8%. Se a mesma sensibilidade fosse observada em uma amostra de 240 pessoas, o IC de 95% seria 92,5-98,0, dando mais garantia de que o teste é altamente sensível.
Em ensaios controlados randomizados (RCTs), resultados não significativos (ou seja, aqueles com P > 0,05) são particularmente suscetíveis a má interpretação. O IC é particularmente útil aqui, pois indica a compatibilidade dos resultados com o efeito verdadeiro clinicamente útil. Por exemplo, em um RCT comparando sutura versus anastomose com grampo no cólon, a infecção da ferida se desenvolveu em 10,9% e 13,5% dos pacientes, respectivamente (P = 0,30). O IC de 95% para essa diferença é de 2,6% (-2 a +8). Mesmo neste estudo, que incluiu 652 pacientes, é provável que haja uma diferença modesta na incidência de infecções decorrentes dos dois procedimentos. Quanto menor o estudo, maior a incerteza. Sung et ai. realizaram um RCT comparando a infusão de octreotida com escleroterapia de emergência para sangramento varicoso agudo em 100 pacientes. No grupo octreotida, a taxa de parada do sangramento foi de 84%; no grupo de escleroterapia - 90%, o que dá P = 0,56. Observe que as taxas de sangramento contínuo são semelhantes às de infecção da ferida no estudo mencionado. Nesse caso, porém, o IC de 95% para diferença nas intervenções é de 6% (-7 a +19). Essa faixa é bastante ampla em comparação com uma diferença de 5% que seria de interesse clínico. É claro que o estudo não exclui uma diferença significativa na eficácia. Portanto, a conclusão dos autores "infusão de octreotida e escleroterapia são igualmente eficazes no tratamento de sangramento de varizes" definitivamente não é válida. Em casos como este em que o IC de 95% para redução absoluta do risco (ARR) inclui zero, como aqui, o IC para NNT (número necessário para tratar) é bastante difícil de interpretar. O NLP e seu IC são obtidos a partir dos recíprocos do ACP (multiplicando-os por 100 se esses valores forem dados como porcentagens). Aqui obtemos NPP = 100: 6 = 16,6 com um IC de 95% de -14,3 a 5,3. Como pode ser visto na nota de rodapé "d" na Tabela. A1.1, este IC inclui valores para NTPP de 5,3 ao infinito e NTLP de 14,3 ao infinito.
Os ICs podem ser construídos para as estimativas ou comparações estatísticas mais comumente usadas. Para RCTs, inclui a diferença entre as proporções médias, riscos relativos, odds ratio e NRRs. Da mesma forma, ICs podem ser obtidos para todas as principais estimativas feitas em estudos de precisão de testes diagnósticos – sensibilidade, especificidade, valor preditivo positivo (todos os quais são proporções simples) e razões de verossimilhança – estimativas obtidas em meta-análises e comparação com controle estudos. Um programa de computador pessoal que abrange muitos desses usos de DI está disponível com a segunda edição do Statistics with Confidence. Macros para calcular ICs para proporções estão disponíveis gratuitamente para Excel e os programas estatísticos SPSS e Minitab em http://www.uwcm.ac.uk/study/medicine/epidemiology_statistics/research/statistics/proportions, htm.
Embora a construção de ICs seja desejável para os resultados primários de um estudo, eles não são necessários para todos os resultados. O IC diz respeito a comparações clinicamente importantes. Por exemplo, ao comparar dois grupos, o IC correto é aquele que é construído para a diferença entre os grupos, conforme os exemplos acima, e não o IC que pode ser construído para a estimativa em cada grupo. Além de ser inútil fornecer ICs separados para as pontuações em cada grupo, essa apresentação pode ser enganosa. Da mesma forma, a abordagem correta ao comparar a eficácia do tratamento em diferentes subgrupos é comparar dois (ou mais) subgrupos diretamente. É incorreto supor que o tratamento é eficaz apenas em um subgrupo se seu IC exclui o valor correspondente a nenhum efeito, enquanto outros não. Os ICs também são úteis ao comparar resultados em vários subgrupos. Na fig. A1.1 mostra o risco relativo de eclâmpsia em mulheres com pré-eclâmpsia em subgrupos de mulheres de um RCT de sulfato de magnésio controlado por placebo.
Arroz. A1.2. O Forest Graph mostra os resultados de 11 ensaios clínicos randomizados de vacina contra rotavírus bovino para prevenção de diarreia versus placebo. O intervalo de confiança de 95% foi usado para estimar o risco relativo de diarreia. O tamanho do quadrado preto é proporcional à quantidade de informação. Além disso, uma estimativa resumida da eficácia do tratamento e um intervalo de confiança de 95% (indicado por um losango) são mostrados. A metanálise utilizou um modelo de efeitos aleatórios que supera alguns pré-estabelecidos; por exemplo, pode ser o tamanho usado no cálculo do tamanho da amostra. Sob um critério mais rigoroso, toda a gama de ICs deve mostrar um benefício que exceda um mínimo predeterminado.
Já discutimos a falácia de considerar a ausência de significância estatística como uma indicação de que dois tratamentos são igualmente eficazes. É igualmente importante não igualar significância estatística com significância clínica. A importância clínica pode ser assumida quando o resultado é estatisticamente significativo e a magnitude da resposta ao tratamento
Estudos podem mostrar se os resultados são estatisticamente significativos e quais são clinicamente importantes e quais não são. Na fig. A1.2 mostra os resultados de quatro tentativas para as quais todo o IC<1, т.е. их результаты статистически значимы при Р <0,05 , . После высказанного предположения о том, что клинически важным различием было бы сокращение риска диареи на 20% (ОР = 0,8), все эти испытания показали клинически значимую оценку сокращения риска, и лишь в исследовании Treanor весь 95% ДИ меньше этой величины. Два других РКИ показали клинически важные результаты, которые не были статистически значимыми. Обратите внимание, что в трёх испытаниях точечные оценки эффективности лечения были почти идентичны, но ширина ДИ различалась (отражает размер выборки). Таким образом, по отдельности доказательная сила этих РКИ различна.
Suponha que temos um grande número de itens com distribuição normal de algumas características (por exemplo, um depósito cheio de vegetais do mesmo tipo, cujo tamanho e peso variam). Você quer saber as características médias de todo o lote de mercadorias, mas não tem tempo nem disposição para medir e pesar cada vegetal. Você entende que isso não é necessário. Mas quantas peças você precisaria levar para inspeção aleatória?
Antes de dar algumas fórmulas úteis para esta situação, vamos relembrar algumas notações.
Primeiro, se medimos todo o armazém de vegetais (esse conjunto de elementos é chamado de população geral), saberíamos com toda a precisão de que dispomos o valor médio do peso de todo o lote. Vamos chamar isso de média X cf .g en . - média geral. Já sabemos o que está completamente determinado se seu valor médio e desvio s forem conhecidos . É verdade, até agora não somos nem X avg. nem s não conhecemos a população em geral. Podemos apenas pegar algumas amostras, medir os valores de que precisamos e calcular para esta amostra o valor médio X sr. na amostra e o desvio padrão S sb.
Sabe-se que se nossa verificação personalizada contiver um grande número de elementos (geralmente n é maior que 30) e eles forem levados realmente aleatório, então s a população em geral quase não diferirá de S ..
Além disso, para o caso de uma distribuição normal, podemos usar as seguintes fórmulas:
Com uma probabilidade de 95%
Com uma probabilidade de 99%
![]()
Em geral, com probabilidade Р (t)
A relação entre o valor de t e o valor da probabilidade P (t), com a qual queremos saber o intervalo de confiança, pode ser extraída da seguinte tabela:
Assim, determinamos em que faixa está o valor médio para a população em geral (com uma dada probabilidade).
A menos que tenhamos uma amostra grande o suficiente, não podemos afirmar que a população tem s = S sel. Além disso, neste caso, a proximidade da amostra com a distribuição normal é problemática. Neste caso, use também S sb em vez na fórmula:

mas o valor de t para uma probabilidade fixa P(t) dependerá do número de elementos na amostra n. Quanto maior n, mais próximo o intervalo de confiança resultante estará do valor dado pela fórmula (1). Os valores t neste caso são retirados de outra tabela (teste t de Student), que disponibilizamos a seguir:
Valores do teste t de Student para probabilidade 0,95 e 0,99

Exemplo 3 30 pessoas foram selecionadas aleatoriamente entre os funcionários da empresa. De acordo com a amostra, descobriu-se que o salário médio (por mês) é de 30 mil rublos com um desvio quadrado médio de 5 mil rublos. Com uma probabilidade de 0,99 determine o salário médio da empresa.
Solução: Por condição, temos n = 30, X cf. =30000, S=5000, P=0,99. Para encontrar o intervalo de confiança, usamos a fórmula correspondente ao critério de Student. De acordo com a tabela para n \u003d 30 e P \u003d 0,99 encontramos t \u003d 2,756, portanto,
Essa. confiança desejada intervalo 27484< Х ср.ген
< 32516.
Assim, com probabilidade de 0,99, pode-se argumentar que o intervalo (27484; 32516) contém o salário médio da empresa.
Esperamos que você use esse método sem necessariamente ter uma planilha com você o tempo todo. Os cálculos podem ser realizados automaticamente no Excel. Enquanto estiver em um arquivo do Excel, clique no botão fx no menu superior. Em seguida, selecione entre as funções o tipo "estatístico", e da lista proposta na caixa - STEUDRASP. Em seguida, no prompt, colocando o cursor no campo "probabilidade", digite o valor da probabilidade recíproca (ou seja, no nosso caso, em vez da probabilidade de 0,95, você precisa digitar a probabilidade de 0,05). Aparentemente, a planilha foi projetada para que o resultado responda à pergunta sobre a probabilidade de estarmos errados. Da mesma forma, no campo "grau de liberdade", insira o valor (n-1) para sua amostra.









