
Для анализа общего качества оцененной линейной регрессии используют обычно коэффициент детерминации, называемый также квадратом коэффициента множественной корреляции. Для случая парной регрессии это квадрат коэффициента корреляции переменных и.
Коэффициент детерминации рассчитывается по формуле:
сумма квадратов остатков регрессии
Фактические и расчетные значения объясняемой переменной.
Общая сумма квадратов.
Он характеризует долю вариации (разброса) зависимой переменой, объясненной с помощью данного уравнения. В качестве меры разброса зависимой переменной обычно используется ее дисперсия, а остаточная вариация может быть измерена как дисперсия отклонений вокруг линии регрессии. Если числитель и знаменатель вычитаемой из единицы дроби разделить на число наблюдений n, то получим, соответственно, выборочные оценки остаточной дисперсии и дисперсии зависимой переменной. Отношение остаточной и общей дисперсии представляют собой долю необъясненной дисперсии. Если же эту долю вычесть из единицы, то получим долю дисперсии зависимой переменной. Объясненной с помощью регрессии. Иногда при расчете коэффициента детерминации для получения несмещенных оценок дисперсии в числителе и знаменателе вычитаемой из единицы дроби делается поправка на число степеней свободы: тогда
Или, для парной регрессии, где число независимым переменных равно 1,
В числителе дроби, которая вычитается из единицы, стоит сумма квадратов отклонений наблюдений от линии регрессии, в знаменателе - от среднего значения переменной. Таким образом, дробь это мала (а коэффициент, очевидно, близок к единице), если разброс точек вокруг линии регрессии значительно меньше, чем вокруг среднего значения.
Метод наименьших квадратов (МНК) позволяет найти прямую, для которой сумма минимальна, а представляет собой одну из возможных линий, для которых выполняется условие. Поэтому величина в числителе вычитаемой из единицы дроби меньше, чем величина в ее знаменателе, - иначе выбираемой по МНК линией регрессии была бы прямая.
Таким образом, коэффициент детерминации является мерой, позволяющей определить, в какой степени найденная регрессионная прямая дает лучший результат для объяснения поведения зависимой переменной, чем просто горизонтальная прямая.
Смысл коэффициента детерминации может быть пояснен и немного иначе. Можно показать, что
где - отклонение -й точки на линии регрессии от.
В данной формуле величина в левой части может интерпретироваться как мера общего разброса (вариации) переменной, первое слагаемое в правой части - как мера остаточного, необъясненного разброса (разброса точек вокруг линии регрессии). Если разделить эту формулу на ее левую часть и перегруппировать члены, то
То есть коэффициент детерминации есть доля объясненной части разброса зависимой переменной (или доля объясненной дисперсии, если разделить числитель и знаменатель на и ().
Часто коэффициент детерминации иллюстрируют следующим образом (рис. 1)
Рисунок 1 Иллюстрированный коэффициент детерминации
Здесь TSS (Total Sum of Squares) - общий разброс переменной, ESS (Explained Sum of Squares) - разброс, объясненный с помощью регрессии, USS (Unexplained Sum of Squares) - разброс, необъясненный с помощью регрессии. Из рисунка видно, что с увеличением объясненной доли разброса коэффициент приближается к единице. Кроме того, из рисунка видно, что с добавлением еще одной переменной обычно увеличивается, однако если объясняющие переменные и сильно коррелируют между собой, то они объясняют одну и ту же часть разброса переменной, и в этом случае трудно идентифицировать вклад каждой из переменных в объяснение поведения.
Если существует статистически значимая линейная связь величин и, то коэффициент близок к единице.
Однако он может быть близким к единице просто в силу того, что обе эти величины имеют выраженный временный тренд, не связанный с их причинно-следственной взаимозависимостью.
В экономике обычно объемные показатели (доход, потребление, инвестиции) имеют такой тренд, а темповые и относительные (производительности, темпы роста, доли, отношения) - не всегда. Поэтому при оценивании линейных регрессий по временным рядам объемных показателей (например, зависимости выпуска от затрат ресурсов или объема потребления от величины дохода) величина обычно очень близка к единице. Это говорит о том, что зависимую переменную нельзя описать просто как равную своему среднему значению, но это и заранее очевидно, раз она имеет временный тренд.
Если имеются не временные ряды, а перекрестная выборка, то есть данные об однотипных объектах в один и тот же момент времени, то для оцененного по ним уравнения линейной регрессии величина не превышает обычно уровня 0,6 - 0,7.
То же самое обычно имеет место и для регрессии по временных рядам, если они не имеют выраженного тренда. В макроэкономике примерами таких зависимостей являются связи относительных, удельных, темповых показателей: зависимость темпа инфляции от уровня безработицы, нормы накопления от величины процентной ставки, темпа прироста выпуска от темпов прироста затрат ресурсов.
Таким образом, при построении макроэкономических моделей, особенно - по временных рядам данных, нужно учитывать, являются входящие в них переменных объемными или относительными, имеют ли они временной тренд.
Точную границу приемлемости показателя указать сразу для всех случаев невозможно. Нужно принимать во внимание и число степеней свободы уравнения, и наличие трендов переменных, и содержательную интерпретацию уравнения. Показатель может оказаться даже отрицательным. Как правило, это случается в уравнении без свободного члена
Оценивание такого уравнения производится, как и в общем случае, по методу наименьших квадратов. Однако множество выбора при этом существенно сужается: рассматриваются не все возможные прямые или гиперплоскости, а только проходящие через начало координат. Величина получается отрицательной в том случае, если разброс значений зависимой переменной вокруг прямой (гиперплоскости) меньше, чем вокруг даже наилучшей прямой (гиперплоскости) из проходящих через начало координат. Отрицательная величина в уравнении говорит о целесообразности введения в него свободного члена. Эта ситуация проиллюстрирована на рис. 2.

Рисунок 2 Иллюстрация введения свободного члена в уравнение
Линия 1 на нем- график уравнения регрессии без свободного члена (он проходит через начало координат), линия 2- со свободным членом (он равен), линия 3 - . Горизонтальная линия 3 дает гораздо меньшую сумму квадратов отклонений, чем линия 1, и поэтому для последней коэффициент детерминации будет отрицательным.
Поправка на число степеней свободы всегда уменьшает значение, поскольку. В результате также может стать отрицательной. Но это означает, что она была близкой к нулю до такой поправки, и объясненная с помощью уравнения регрессии доля дисперсии зависимой переменной очень мала.
В пунктах 3.3, 4.1рассмотрена постановка задачи оценивания уравнения линейной регрессии, показан способ ее решения. Однако оценка параметров конкретного уравнения является лишь отдельным этапом длительного и сложного процесса построения эконометрической модели.Первое же оцененное уравнение очень редко является удовлетворительным во всех отношениях. Обычно приходится постепенно подбирать формулу связи и состав объясняющих переменных, анализируя на каждом этапе качество оцененной зависимости. Этот анализ качества включает статистическую и содержательную составляющую. Проверка статистического качества оцененного уравнения состоит из следующих элементов:
проверка статистической значимости каждого коэффициента уравнения регрессии;
проверка общего качества уравнения регрессии;
проверка свойств данных, выполнение которых предполагалось
при оценивании уравнения.
Под содержательной составляющей анализа качества понимается рассмотрение экономического смысла оцененного уравнения регрессии: действительно ли значимыми оказались объясняющие факторы, важные с точки зрения теории; положительны или отрицательны коэффициенты, показывающие направление воздействия этих факторов; попали ли оценки коэффициентов регрессии в предполагаемые из теоретических соображений интервалы.
Методика проверки статистической значимости каждого отдельного коэффициента уравнения линейной регрессии была рассмотрена в предыдущей главе. Перейдем теперь к другим этапам проверки качества уравнения.
Для анализа общего качества оцененной линейной регрессии используют обычно коэффициент детерминации R 2 . Для случая парной регрессии это квадрат коэффициента корреляции переменныхх иy . Коэффициент детерминации рассчитывается по формуле
Коэффициент детерминации характеризует долю вариации (разброса) зависимой переменной, объясненной с помощью данного уравнения. В качестве меры разброса зависимой переменной обычно используется ее дисперсия, а остаточная вариация может быть измерена как дисперсия отклонений вокруг линии регрессии. Если числитель и знаменатель вычитаемой из единицы дроби разделить на число наблюденийп, то получим, соответственно, выборочные оценки остаточной дисперсии и дисперсии зависимой переменнойу. Отношение остаточной и общей дисперсий представляет собой долю необъясненной дисперсии. Если же эту долю вычесть из единицы, то получим долю дисперсии зависимой переменной, объясненной с помощью регрессии. Иногда при расчете коэффициента детерминации для получения несмещенных оценок дисперсии в числителе и знаменателе вычитаемой из единицы дроби делается поправка на число степеней свободы; тогда
 .
.
или, для парной регрессии, где число независимых переменных т равно 1,

В числителе дроби, которая вычитается
из единицы, стоит сумма квадратов
отклонений наблюдений у
i
от линии регрессии, в знаменателе - от
среднего значения переменнойу.
Таким образом,дробь эта мала (а
коэффициент
R
2
,
очевидно, близок к единице), если разброс
точек вокруг линии регрессии значительно
меньше, чем вокруг среднего значения
.
МНК позволяет найти прямую, для которой
суммае
i
2
минимальна, а представляет
собой одну из возможных линий, для
которых выполняется условие.
Поэтому величина в числителе вычитаемой
из единицы дроби меньше, чем величина
в ее знаменателе, - иначе выбиремой по
МНК линией регрессии была бы прямая
представляет
собой одну из возможных линий, для
которых выполняется условие.
Поэтому величина в числителе вычитаемой
из единицы дроби меньше, чем величина
в ее знаменателе, - иначе выбиремой по
МНК линией регрессии была бы прямая .
Таким образом, коэффициент детерминацииR
2
является мерой,
позволяющей определить, в какой степени
найденная регрессионная прямая дает
лучший результат для объяснения поведения
зависимой переменнойу,
чем просто
горизонтальная прямая
.
Таким образом, коэффициент детерминацииR
2
является мерой,
позволяющей определить, в какой степени
найденная регрессионная прямая дает
лучший результат для объяснения поведения
зависимой переменнойу,
чем просто
горизонтальная прямая .
.
Смысл коэффициента детерминации может
быть пояснен и немного иначе. Можно
показать, что
 ,
гдеk
i
=
,
гдеk
i
= - отклонениеi
‑
й
точки на линии регрессии от
- отклонениеi
‑
й
точки на линии регрессии от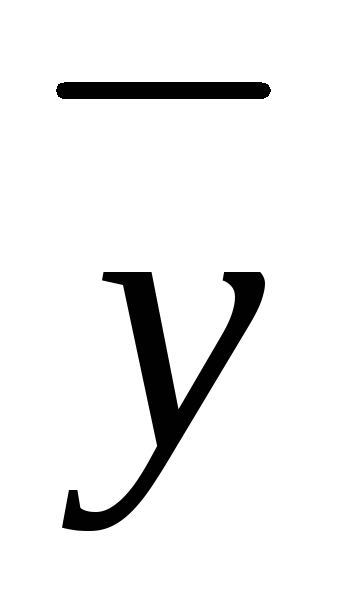 .
В данной формуле величина в левой части
может интерпретироваться как мера
общего разброса (вариации) переменнойу,
первое слагаемое в правой части
.
В данной формуле величина в левой части
может интерпретироваться как мера
общего разброса (вариации) переменнойу,
первое слагаемое в правой части -
как мера разброса, объясненного с помощью
регрессии, и второе слагаемое
-
как мера разброса, объясненного с помощью
регрессии, и второе слагаемое -
как мера остаточного, необъясненного
разброса (разброса точек вокруг линии
регрессии). Если разделить эту формулу
на ее левую часть и перегруппировать
члены, то
-
как мера остаточного, необъясненного
разброса (разброса точек вокруг линии
регрессии). Если разделить эту формулу
на ее левую часть и перегруппировать
члены, то
 ,
то есть коэффициент детерминацииR
2 есть доля объясненной части разброса
зависимой переменной (или доля объясненной
дисперсии, если разделить числитель и
знаменатель наn
илип-
1).
Часто коэффициент детерминацииR
2
иллюстрируют рис.
4.2
,
то есть коэффициент детерминацииR
2 есть доля объясненной части разброса
зависимой переменной (или доля объясненной
дисперсии, если разделить числитель и
знаменатель наn
илип-
1).
Часто коэффициент детерминацииR
2
иллюстрируют рис.
4.2

Рис. 4.2.
Здесь TSS (To tal Sum of Squares ) - общий разброс переменнойу, Е SS (Explained Sum of Squares ) - разброс, объясненный с помощью регрессии, USS (Unexplained Sum of Squares ) -разброс, необъясненный с помощью регрессии. Из рисунка видно, что с увеличением объясненной доли разброса коэффициентR 2 - приближается к единице. Кроме того, из рисунка видно, что с добавлением еще одной переменнойR 2 обычно увеличивается, однако если объясняющие переменныех 1 их 2 сильно коррелируют между собой, то они объясняют одну и ту же часть разброса переменнойу, и в этом случае трудно идентифицировать вклад каждой из переменных в объяснение поведенияу.
Если существует статистически значимая линейная связь величин х иу , то коэффициентR 2 близок к единице. Однако он может быть близким к единице просто в силу того, что обе эти величины имеют выраженный временной тренд, не связанный с их причинно-следственной взаимозависимостью. В экономике обычно объемные показатели (доход, потребление, инвестиции) имеют такой тренд, а темповые и относительные (производительности, темпы роста, доли, отношения) - не всегда. Поэтому при оценивании линейных регрессий по временным рядам объемных показателей (например, зависимости выпуска от затрат ресурсов или объема потребления от величины дохода) величинаR 2 обычно очень близка к единице. Это говорит о том, что зависимую переменную нельзя описать просто как равную своему среднему значению, но это и заранее очевидно, раз она имеет временной тренд.
Если имеются не временные ряды, а перекрестная выборка, то есть данные об однотипных объектах в один и тот же момент времени, то для оцененного по ним уравнения линейной регрессии величина R 2 не превышает обычно уровня 0,6-0,7. То же самое обычно имеет место и для регрессии по временным рядам, если они не имеют выраженного тренда. В макроэкономике примерами таких зависимостей являются связи относительных, удельных, темповых показателей: зависимость темпа инфляции от уровня безработицы, нормы накопления от величины процентной ставки, темпа прироста выпуска от темпов прироста затрат ресурсов. Таким образом, при построении макроэкономических моделей, особенно - по временным рядам данных, нужно учитывать, являются входящие в них переменные объемными или относительными, имеют ли они временной тренд 1 .
Точную границу приемлемости показателя
R
2 указать сразу для всех
случаев невозможно. Нужно принимать во
внимание и число степеней свободы
уравнения, и наличие трендов переменных,
и содержательную интерпретацию уравнения.
ПоказательR
2
может
оказаться даже отрицательным. Как
правило, это случается в уравнении без
свободного членау = .
Оценивание такого уравнения производится,
как и в общем случае, по методу наименьших
квадратов. Однако множество выбора при
этом существенно сужается: рассматриваются
не все возможные прямые или гиперплоскости,
а только проходящие через начало
координат. ВеличинаR
2
получится отрицательной в том случае,
если разброс значений зависимой
переменной вокруг прямой (гиперплоскости)
.
Оценивание такого уравнения производится,
как и в общем случае, по методу наименьших
квадратов. Однако множество выбора при
этом существенно сужается: рассматриваются
не все возможные прямые или гиперплоскости,
а только проходящие через начало
координат. ВеличинаR
2
получится отрицательной в том случае,
если разброс значений зависимой
переменной вокруг прямой (гиперплоскости) меньше, чем вокруг даже наилучшей прямой
(гиперплоскости) из проходящих через
начало координат. Отрицательная величинаR
2
в уравнении
меньше, чем вокруг даже наилучшей прямой
(гиперплоскости) из проходящих через
начало координат. Отрицательная величинаR
2
в уравнении
 говорит
о целесообразности введения в него
свободного члена. Эта ситуация
проиллюстрирована на рис. 4.3.
говорит
о целесообразности введения в него
свободного члена. Эта ситуация
проиллюстрирована на рис. 4.3.
Линия 1 на нем - график уравнения регрессии
без свободного члена (он проходит через
начало координат), линия 2 - со свободным
членом (он равен а
0
), линия
3 - .
Горизонтальная линия 3 дает гораздо
меньшую сумму квадратов отклоненийе
i
,
чем линия 1, и поэтому для последней
коэффициент детерминацииR
2 будет отрицательным.
.
Горизонтальная линия 3 дает гораздо
меньшую сумму квадратов отклоненийе
i
,
чем линия 1, и поэтому для последней
коэффициент детерминацииR
2 будет отрицательным.

Рис. 4.3. Линии уравнений линейной регрессии у=f(х) без свободного члена (1) и со свободным членом (2)
Поправка на число степеней свободы всегда уменьшает значение R 2 , поскольку(п- 1)>(п-т- 1). В результате величинаR 2 также может стать отрицательной. Но это означает, что она была близкой к нулю до такой поправки, и объясненная с помощью уравнения регрессии доля дисперсии зависимой переменной очень мала.
Коэффициент детерминации.
Анализ проводится, например, по коэффициенту детерминации
Альтернативным показателем степени зависимости между двумя переменными является коэффициент детерминации, представляющий собой возведенный в квадрат коэффициент корреляции (г2). Коэффициент детерминации выражается в процентах и отражает величину изменения результативного показателя (у) за счет изменения другой переменной - факторного показателя (х).
По результатам нашего примера, приведенного выше, коэффициент детерминации составил г = 0,471 б2 = 0,2224 = 22,24%. Это означает, что более 22% изменений в выручке от продаж связаны с изменениями в расходах на рекламу.
Определите коэффициент детерминации по условию теста 1. Интерпретируйте уровень этого коэффициента.
В случаях, когда трудно обосновать форму зависимости, решение задачи можно провести по разным моделям и сравнить полученные результаты. Адекватность разных моделей фактическим зависимостям проверяется по критерию Фишера , показателю средней ошибки аппроксимации и величине множественного коэффициента детерминации, о которых речь пойдет несколько позже (см. 7.4).
Коэффициент детерминации модели, равный квадрату приведенного коэффициента множественной корреляции , составил 99,31% стандартная ошибка модели оказалась равна 4415 тыс. руб., / статистика Фишера - 4,415, а уровень значимости гипотезы об отсутствии связи - менее 0,01%.
Это выражение соответствует выражению т)2 (см. формулу (8.2)). Тождество коэффициента детерминации и квадрата корреляционного отношения служит основанием для интерпретации величины г2л, как доли общей дисперсии результативного признака у, которая объясняется вариацией признака-фактора х (и связью между вариацией обоих признаков). Собственно говоря, основным показателем тесноты связи и следовало бы считать коэффициент детерминации
Коэффициент детерминации г2 = 71,3%, т. е. вариация возраста супруга или супруги на 71% зависит от вариации возраста второй половины. Связь весьма тесная.
Поскольку г 2 - аналог коэффициента детерминации, можно сделать вывод, что 42,2% вариации себестоимости молока в совокупности 136 предприятий были связаны с вариацией продуктивности коров (и с факторами, варьирующими согласованно с продуктивностью в соответствии с ранее сделанной оговоркой об интерпретации парных связей).
Здесь Ry2 - коэффициент детерминации для уравнения со всеми k факторами. Числитель (8.43) и есть дополнительно объясняемая часть вариации у при включении фактора хт в уравнение после всех остальных факторов. В нашем примере, используя ранее рассчитанную величину R2 = 0,5765, при включении в анализ фактора х3 получаем
Однако крупнейшим недостатком такого способа разложения R2 является зависимость величин р2 от принятого порядка включения факторов в уравнение регрессии . Первый включаемый фактор забирает в свою пользу львиную часть системного эффекта , а на долю последнего фактора остается ничтожная часть. Например, если переставить местами факторы дс, и хэ, а также вычислить по рекуррентной формуле двухфакторный коэффициент детерминации /Z2 x = 0,8035, то получим результаты , отличные от предыдущих
Признаки-факторы должны находиться в причинной связи с результативным признаком (следствием). Поэтому, недопустимо, например, в модель себестоимости у вводить в качестве одного из факторов Xj коэффициент рентабельности , хотя включение такого фактора значительно повышает коэффициент детерминации.
Принцип простоты предпочтительнее модель с меньшим числом факторов при том же коэффициенте детерминации или даже при несущественно меньшем коэффициенте.
Предельно возможный избыток был бы в том случае, если бы не было гетерогенных сочетаний, т. е. Аб и Ба. Он составляет 140 + 80 + 230 = 450. Сам же показатель тесноты связи - отношение фактического излишка к предельному 140 450 = 0,311. Как видим, этот показатель близок к коэффициенту ассоциации, но обладает чрезвычайно логичной и ясной интерпретацией связь составляет 0,311 или 31,1%, от предельно возможной функциональной . Этот показатель - аналог не коэффициента корреляции , а коэффициента детерминации. Поэтому правомерно обозначить его как R2 или г 2. Он имеет вид
Коэффициент детерминации г2, равен 0,88, или 88% колебаний себестоимости картофеля связаны с колебаниями урожайности. Положительны лишь три произведения отклонения мг иу, притом наименьшие.
Проведение анализа по отдельным единицам с использованием уравнения регрессии обычно основывается на разложении величины отклонения от общей средней (у, - у) на две составляющие (у, - у) и (у, - у,). Если в уравнение регрессии входят все важные и существенные факторы, от которых- зависит величина результативного признака , и коэффициент детерминации близок к единице, то остальные, не включенные в уравнение факторы, характеризуют индивидуальные, несущественные особенности, зачастую не имеющие количественного выражения. В этом случае разница (у, - у/) образуется за счет несовпадения интенсивности воздействия на у всех учтенных факторов в условиях данной /-и единицы и средней интенсивности их воздействия, выраженной в величинах коэффициентов регрессии, входящих в расчетное значение yf. Это дает право интерпретировать разницу (у, -у,) или отношение у,/у, как показатель того, как эффективность использования учтенных факторов у /-и единицы соотносится со средней эффективностью их использования. Разница (у, - у) возникает за счет различия в значениях учтенных факторов для данной /-и единицы и в среднем по совокупности. Такое разложение дает возможность выявить резервы, имеющиеся у каждой отдельной единицы, в части эффективности ис- пользования факторов и в части их уровня.
Учитывая сравнительно низкие значения отчетного и базисного коэффициентов детерминации (/ 0 = 0,8] 54, г2, = 0,7974), разница фактической и расчетной величин (V,- V) выражает не только различия в эффективности использования учтенного фактора - мощности пласта - на данной конкретной шахте по сравнению со средней эффективностью по тресту, но и влияние неучтенных в уравнении регрессии факторов.
I Третий способ построения многомерных средних долей не требует привлечения каких-либо субъективных экспертных оценок - используется только информация, содержащаяся в исходных долях. Более информативным, а следовательно, весомым признается тот признак, который имеет более высокий коэффициент детерминации долей со всеми остающимися признаками. Вычислив попарные и средние коэффициенты детерминации, примем меньший из них за единицу (один балл) и получим баллы для других признаков, как отношения их средних коэффициентов детерминации к меньшему (см. табл. 11.9).
Где I - единичная квадратная матрица размера n x n.
Итак, у нас есть данные, состоящие из k наблюдений величин Y и Xi и мы хотим оценить коэффициенты. Стандартным методом для нахождения оценок коэффициентов является метод наименьших квадратов . И аналитическое решение, которое можно получить, применив этот метод, выглядит так:
где b
с крышкой - оценка вектора коэффициентов, y
- вектор значений зависимой величины, а X - матрица размера k x n+1 (n - количество предикторов, k - количество наблюдений), у которой первый столбец состоит из единиц, второй - значения первого предиктора, третий - второго и так далее, а строки соответствуют имеющимся наблюдениям.
Рассмотрим вывод функции summary.lm().
Сначала идет строка, которая напоминает, как строилась модель.
Затем идет информация о распределении остатков: минимум, первая квартиль, медиана, третья квартиль, максимум. В этом месте было бы полезно не только посмотреть на некоторые квантили остатков, но и проверить их на нормальность, например тестом Шапиро-Уилка.
Далее - самое интересное - информация о коэффициентах. Здесь потребуется немного теории.
Сначала выпишем следующий результат:
при этом сигма в квадрате с крышкой является несмещенной оценкой для реальной сигмы в квадрате. Здесь b
- реальный вектор коэффициентов, а эпсилон с крышкой - вектор остатков, если в качестве коэффициентов взять оценки, полученные методом наименьших квадратов. То есть при предположении, что ошибки распределены нормально, вектор коэффициентов тоже будет распределен нормально вокруг реального значения, а его дисперсию можно несмещенно оценить. Это значит, что можно проверять гипотезу на равенство коэффициентов нулю, а следовательно проверять значимость предикторов, то есть действительно ли величина Xi сильно влияет на качество построенной модели.
Для проверки этой гипотезы нам понадобится следующая статистика, имеющая распределение Стьюдента в том случае, если реальное значение коэффициента bi равно 0:
где![]() - стандартная ошибка оценки коэффициента, а t(k-n-1) - распределение Стьюдента с k-n-1 степенями свободы.
- стандартная ошибка оценки коэффициента, а t(k-n-1) - распределение Стьюдента с k-n-1 степенями свободы.
Теперь все готово для продолжения разбора вывода функции summary.lm().
Итак, далее идут оценки коэффициентов, полученные методом наименьших квадратов, их стандартные ошибки, значения t-статистики и p-значения для нее. Обычно p-значение сравнивается с каким-нибудь достаточно малым заранее выбранным порогом, например 0.05 или 0.01. И если значение p-статистики оказывается меньше порога, то гипотеза отвергается, если же больше, ничего конкретного, к сожалению, сказать нельзя. Напомню, что в данном случае, так как распределение Стьюдента симметричное относительно 0, то p-значение будет равно 1-F(|t|)+F(-|t|), где F - функция распределения Стьюдента с k-n-1 степенями свободы. Также, R любезно обозначает звездочками значимые коэффициенты, для которых p-значение достаточно мало. То есть, те коэффициенты, которые с очень малой вероятностью равны 0. В строке Signif. codes как раз содержится расшифровка звездочек: если их три, то p-значение от 0 до 0.001, если две, то оно от 0.001 до 0.01 и так далее. Если никаких значков нет, то р-значение больше 0.1.
В нашем примере можно с большой уверенностью сказать, что предикторы Elevation и Adjacent действительно с большой вероятностью влияют на величину Species, а вот про остальные предикторы ничего определенного сказать нельзя. Обычно, в таких случаях предикторы убирают по одному и смотрят, насколько изменяются другие показатели модели, например BIC или Adjusted R-squared, который будет разобран далее.
Значение Residual standart error соответствует просто оценке сигмы с крышкой, а степени свободы вычисляются как k-n-1.
А теперь самая важные статистики, на которые в первую очередь стоит смотреть: R-squared и Adjusted R-squared:
где Yi - реальные значения Y в каждом наблюдении, Yi с крышкой - значения, предсказанные моделью, Y с чертой - среднее по всем реальным значениям Yi.![]()
Начнем со статистики R-квадрат или, как ее иногда называют, коэффициента детерминации. Она показывает, насколько условная дисперсия модели отличается от дисперсии реальных значений Y. Если этот коэффициент близок к 1, то условная дисперсия модели достаточно мала и весьма вероятно, что модель неплохо описывает данные. Если же коэффициент R-квадрат сильно меньше, например, меньше 0.5, то, с большой долей уверенности модель не отражает реальное положение вещей.
Однако, у статистики R-квадрат есть один серьезный недостаток: при увеличении числа предикторов эта статистика может только возрастать. Поэтому, может показаться, что модель с большим количеством предикторов лучше, чем модель с меньшим, даже если все новые предикторы никак не влияют на зависимую переменную. Тут можно вспомнить про принцип бритвы Оккама . Следуя ему, по возможности, стоит избавляться от лишних предикторов в модели, поскольку она становится более простой и понятной. Для этих целей была придумана статистика скорректированный R-квадрат. Она представляет собой обычный R-квадрат, но со штрафом за большое количество предикторов. Основная идея: если новые независимые переменные дают большой вклад в качество модели, значение этой статистики растет, если нет - то наоборот уменьшается.
Для примера рассмотрим ту же модель, что и раньше, но теперь вместо пяти предикторов оставим два:
> lm2<-lm(Species~Elevation+Adjacent, data=gala)
> summary(lm2)
Call:
lm(formula = Species ~ Elevation + Adjacent, data = gala)
Residuals:
Min 1Q Median 3Q Max
-103.41 -34.33 -11.43 22.57 203.65
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.43287 15.02469 0.095 0.924727
Elevation 0.27657 0.03176 8.707 2.53e-09 ***
Adjacent -0.06889 0.01549 -4.447 0.000134 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 60.86 on 27 degrees of freedom
Multiple R-squared: 0.7376, Adjusted R-squared: 0.7181
F-statistic: 37.94 on 2 and 27 DF, p-value: 1.434e-08
Как можно увидеть, значение статистики R-квадрат снизилось, однако значение скорректированного R-квадрат даже немного возросло.
Теперь проверим гипотезу о равенстве нулю всех коэффициентов при предикторах. То есть, гипотезу о том, зависит ли вообще величина Y от величин Xi линейно. Для этого можно использовать следующую статистику, которая, если гипотеза о равенстве нулю всех коэффициентов верна, имеет
Таким образом можно выделить следующие свойства коэффициента детерминации:
1. ; в силу определения
2. =0;в этом случае RSS = 0, т. е. наша регрессия не объясняет, ничего не дает по сравнению с тривиальным прогнозом. Данные позволяют сделать вывод о независимости y и x, изменение в переменной x никак не влияет на изменение среднего значения переменной y. То есть увеличивается разброс точек на корреляционном поле относительно построенной линии регрессии(или статистическая зависимость очень слабая, или уравнение регрессии подобрано неверно).
3. =1; в этом случае все точки () лежат на одной прямой (ESS = 0). Тогда на основании имеющихся данных можно сделать вывод о наличии функциональной, а именно, линейной, зависимости между переменными y и x. Изменение переменной y полностью объясняется изменением переменной x.Для парной линей регрессии коэффициент детерминации точно равен квадрату коэффициента корреляции:
Вообще говоря, значение коэффициента детерминации не говорит о том, есть ли между факторами зависимость и насколько она тесная. Оно говорит только о качестве того уравнения, которое мы построили.
Удобно сравнивать коэффициенты детерминации для нескольких разных уравнений регрессии построенных по одним и тем же данным наблюдений. Из нескольких уравнений лучше то, у которого больше коэффициент детерминации.
3. Скорректированный коэффициент детерминации
Одним из свойств коэффициента детерминации является то, что это не убывающая функция от числа факторов, входящих в модель. Это следует из определения детерминации. Действительно в равенстве
Числитель не зависит, а знаменатель зависит от числа факторов модели. Следовательно, с увеличением числа независимых переменных в модели, коэффициент детерминации никогда не уменьшается. Тогда, если сравнить две регрессионные модели с одной и тоже зависимой переменной, но разным числом факторов, то более высокий коэффициент детерминации будет получен в модели с большим числом факторов. Поэтому необходимо скорректировать коэффициент детерминации с учетом количества факторов, входящих в модель.
Скорректированный (исправленный или оцененный) коэффициент детерминации определяют следующим образом:

Свойства скорректированного коэффициента детерминации:
1. Несложно заметить что при >1 исправленный коэффициент детерминации меньше коэффициента детерминации ().
2. , но может принимать отрицательные значения. При этом, если скорректированный принимает отрицательное значение, то принимает значение близкое к нулю ().
Таким образом скорректированный коэффициент детерминации является попыткой устранить эффект, связанный с ростом R 2 при увеличении числа регрессоров. - "штраф" за увеличение числа независимых переменных.









